Overview概述
World models have emerged as a foundational paradigm for autonomous driving, enabling data synthesis, closed-loop training, and closed-loop simulation. Recent work has converged toward a hybrid reconstruction-generation paradigm that first constructs a 3D scene representation from multi-view observations, then leverages the geometric prior to condition video generation. Despite promising results, existing methods face three persistent bottlenecks: per-scene 3D Gaussian optimization requires multi-hour training and produces ghosting artifacts at scale; causal generation models lack strong scene priors and require hundreds of denoising steps; and reconstruction and generation remain loosely coupled, making it difficult to reconcile geometric fidelity with generative diversity.
This report presents a unified framework that addresses all three challenges. WorldRec replaces costly per-scene optimization with sparse-query aggregation, completing reconstruction in ~10 seconds while eliminating ghosting artifacts. WorldGen combines bidirectional pretraining with progressive causal fine-tuning (Teacher Forcing → ODE distillation → DMD) to achieve stable generation of up to one-minute videos at 0.19s/frame. The Joint World Model tightly couples both modules through incremental scene fusion and ego-projected rendered-prior conditioning, yielding synergistic gains in temporal stability, cross-view consistency, and visual fidelity.
世界模型已成为自动驾驶的基础范式,支撑数据合成、闭环训练与闭环仿真三类核心应用。近年来,该领域逐步汇聚为"重建-生成"混合范式:先从多视角观测重建 3D 场景,再以几何先验条件化视频生成。然而,现有方法仍面临三大瓶颈:逐场景 3D Gaussian 优化耗时数小时且存在重影伪影;因果生成模型缺乏场景先验且推理步数过多;重建与生成耦合过浅,难以兼顾几何保真度与生成多样性。
本报告提出一个系统解决上述挑战的统一框架。WorldRec 以稀疏查询聚合替代逐场景优化,约 10 秒完成重建并消除重影伪影。WorldGen 通过双向预训练与递进因果微调(Teacher Forcing → ODE 蒸馏 → DMD)实现以 0.19 秒/帧生成最长 1 分钟的稳定视频。联合世界模型通过增量场景融合与自车投影渲染先验条件将两者紧密耦合,在时序稳定性、跨视角一致性和视觉保真度三个维度上实现协同增益。
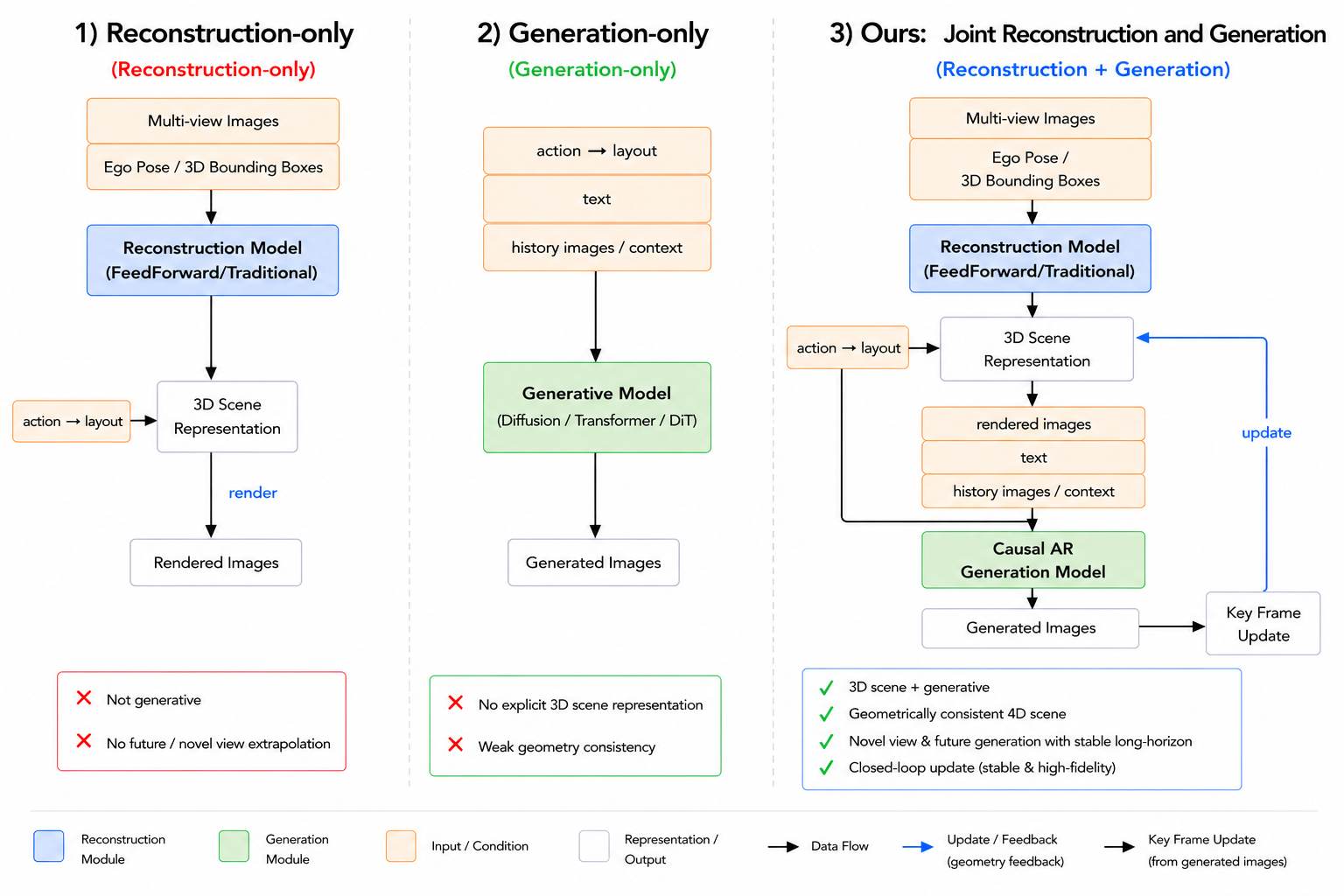
Table 1: Comparison of different world modeling paradigms
表1:不同世界建模范式对比
| Capability能力 | Recon-only仅重建 | Gen-only仅生成 | NeoVerse | AlpaDreams | OursOurs |
|---|---|---|---|---|---|
| Explicit 3D Scene显式 3D 场景 | ✓ | ✗ | ✓ | ✗ | ✓ |
| Generative Capability生成能力 | ✗ | ✓ | ✓ | ✓ | ✓ |
| Novel View Synthesis新视角合成 | ✓ | ✓ | ✓ | ✓ | ✓ |
| Future Prediction未来预测 | ✗ | ✓ | ✓ | ✓ | ✓ |
| Geometry Consistency几何一致性 | Strong强 | Weak弱 | Medium中 | Weak弱 | Strong强 |
| Long-horizon Stability长时序稳定性 | Static静态 | Drift漂移 | Medium中 | Medium中 | Stable稳定 |
Method方法
2.1 WorldRec
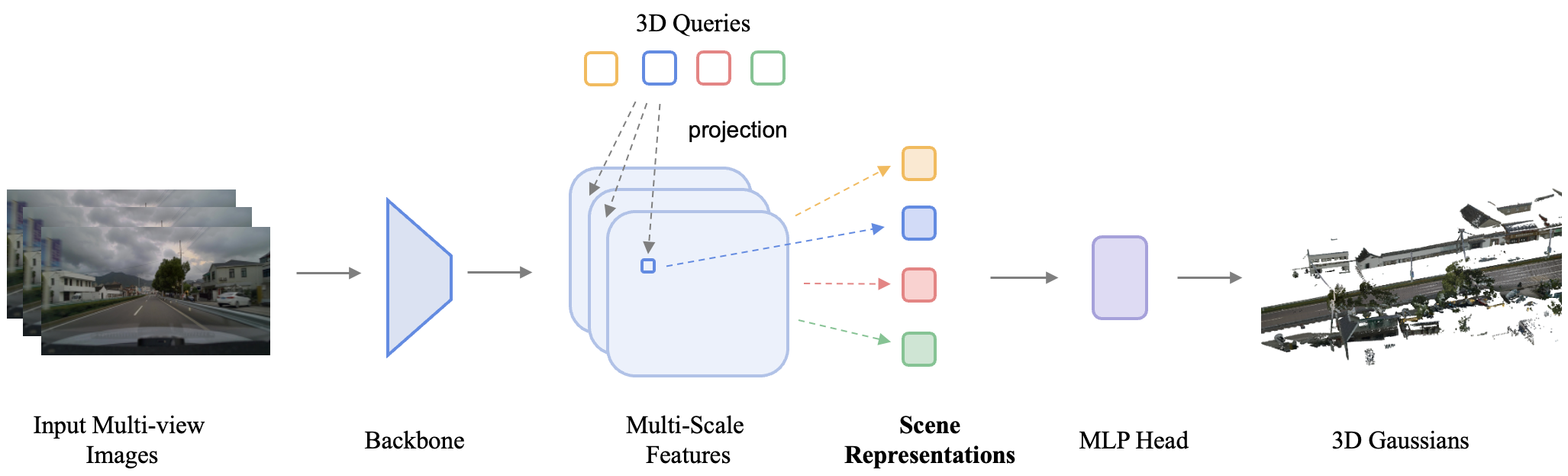
Most existing feedforward methods predict pixel-aligned 3D Gaussians via a DPT head, causing ghosting artifacts and Gaussian primitive explosion. WorldRec instead represents scenes as compact sparse tokens: each token aggregates features from multi-view, multi-temporal observations through a visibility-aware attention mechanism, explicitly enforcing multi-view consistency and yielding compact high-fidelity 3D Gaussian representations. Scene reconstruction from a 10-second clip is accomplished in ~10 seconds — versus ~4 hours for per-scene optimization baselines.
现有前馈方法通过 DPT 头预测像素对齐的 3D Gaussian,导致重影伪影与基元数量爆炸。WorldRec 通过稀疏 token 表示场景:每个 token 通过可见性感知注意力机制聚合多视角、多时刻特征,天然保证跨视角一致性,输出紧凑的高保真 3D Gaussian 表征。10 秒视频片段的场景重建仅需约 10 秒,而逐场景优化基线需要约 4 小时。
2.2 WorldGen
WorldGen adopts a Diffusion Transformer (DiT) backbone and a two-stage training framework: bidirectional pretraining → causal fine-tuning. Stage 1 trains with full bidirectional temporal attention to learn global spatiotemporal distributions. Stage 2 introduces a causal mask and progressively refines the model through Teacher Forcing (causal constraint), ODE distillation (50 steps → 4 steps, 12× speedup), and DMD (closes train-inference distribution gap) — achieving high-quality real-time causal video generation.
WorldGen 采用 Diffusion Transformer(DiT)骨干网络与两阶段训练框架:双向预训练 → 因果微调。第一阶段以全双向时序注意力训练,学习全局时空分布。第二阶段引入因果掩码,通过 Teacher Forcing(因果约束)、ODE 蒸馏(50 步 → 4 步,提速约 12 倍)、DMD(消除暴露偏差)三阶段递进微调,实现高质量实时因果视频生成。
2.3 Joint World Model联合世界模型
The Joint World Model deeply integrates WorldRec and WorldGen so that each module's strengths compensate for the other's limitations. WorldRec provides reliable 4D spatial anchors that prevent geometric drift during generation; WorldGen fills unseen regions with coherent content that reconstruction alone cannot synthesize.
联合世界模型将 WorldRec 与 WorldGen 深度融合,使两个模块的优势相互补充。WorldRec 提供可靠的 4D 空间锚点,防止生成过程中的几何漂移;WorldGen 在重建无法覆盖的未观测区域生成一致内容。
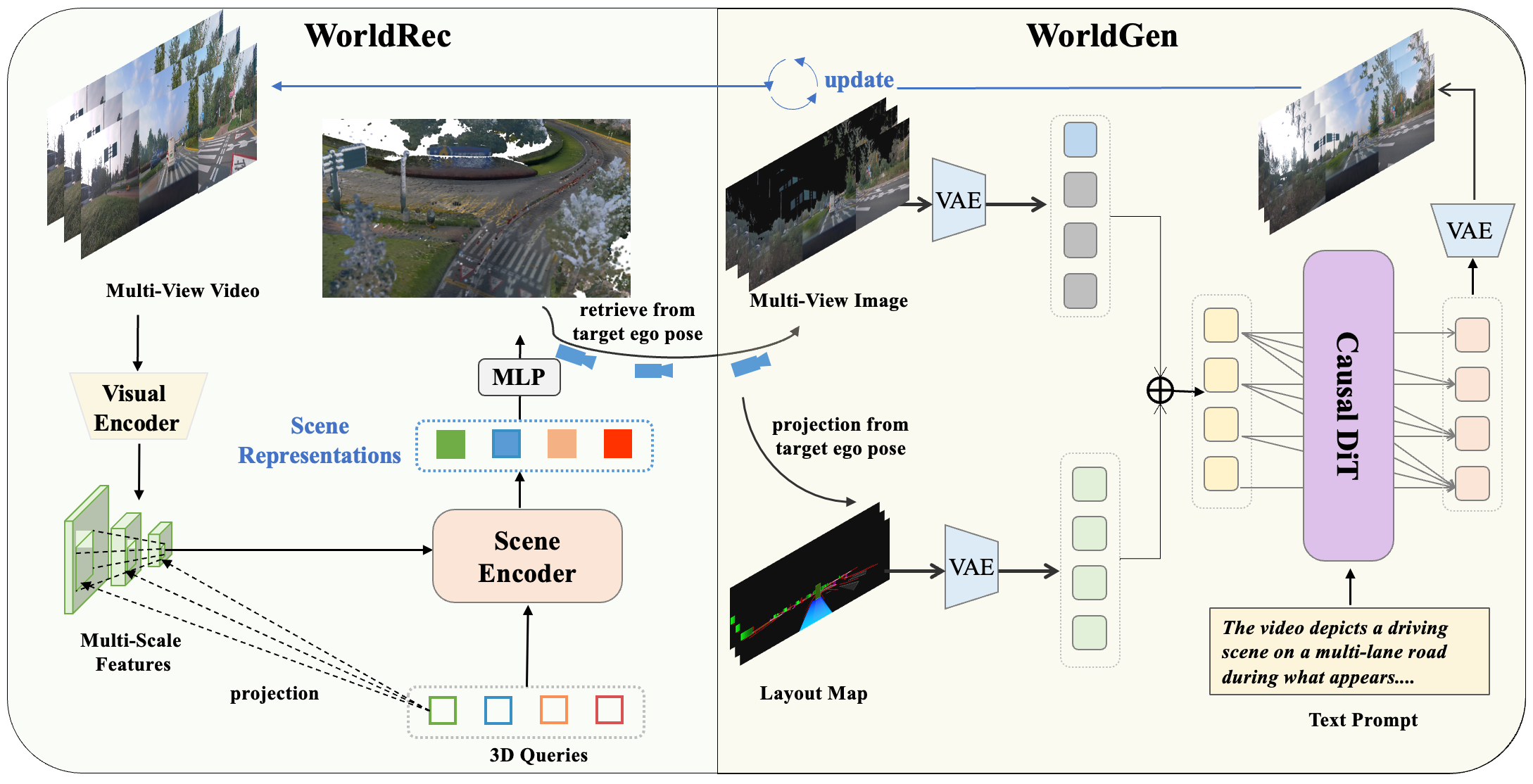
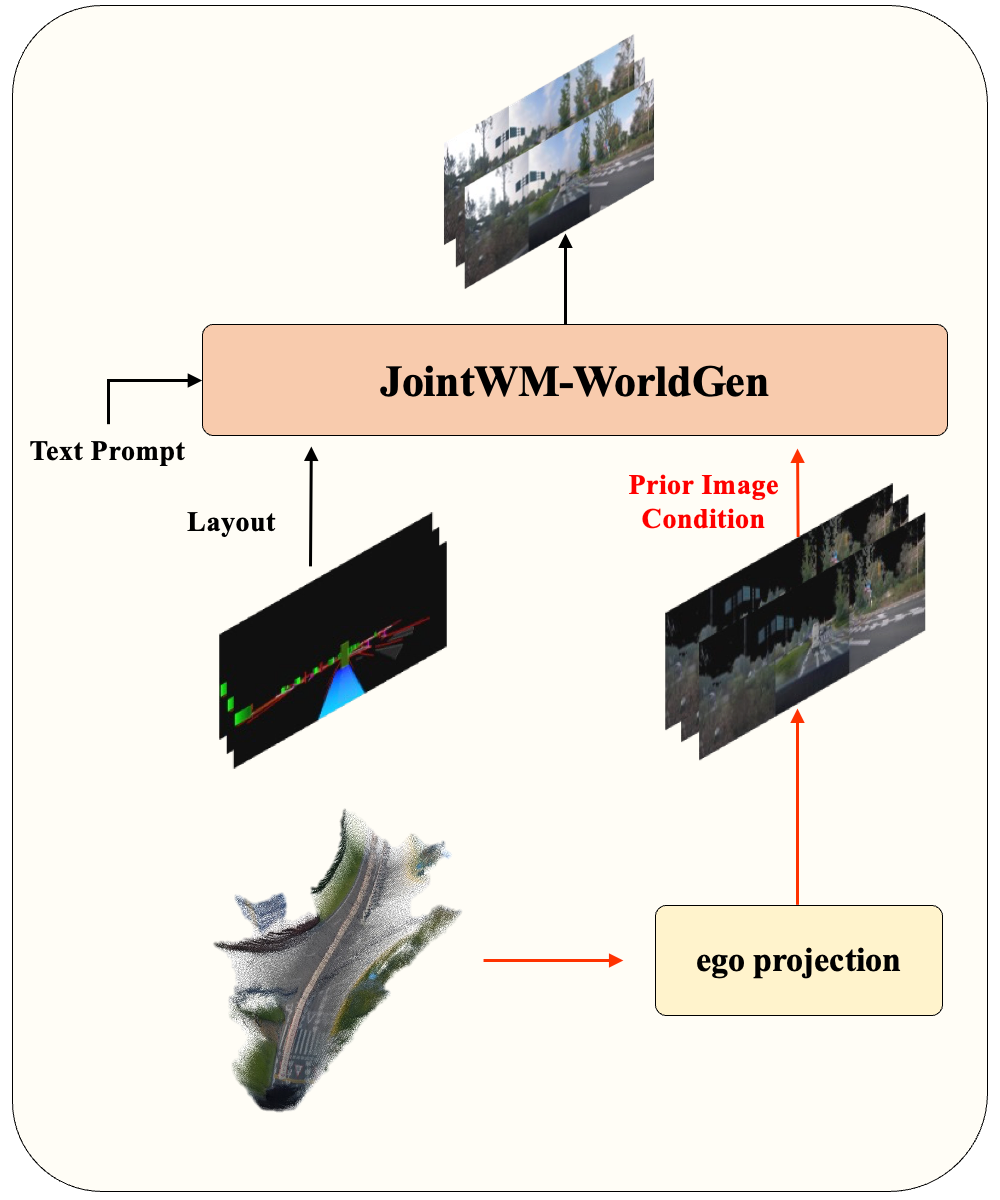
To enable tight coupling, both modules are adapted: WorldRec gains incremental reconstruction via scene fusion — new observations update and extend the existing Gaussian representation, enabling larger scenes as the vehicle moves. WorldGen gains rendered-RGB conditioning — scene tokens are rasterized to target views, producing partial reference images that are injected as additional conditioning, guiding synthesis in unobserved regions.
为实现紧密耦合,两个模块各自适配:WorldRec 通过场景融合支持增量式重建——新帧到来时更新并扩展已有高斯表征,支持更大范围场景重建。WorldGen 支持渲染 RGB 条件——场景 token 被光栅化为目标视角的参考图像,作为额外条件注入 DiT,引导未观测区域的生成。
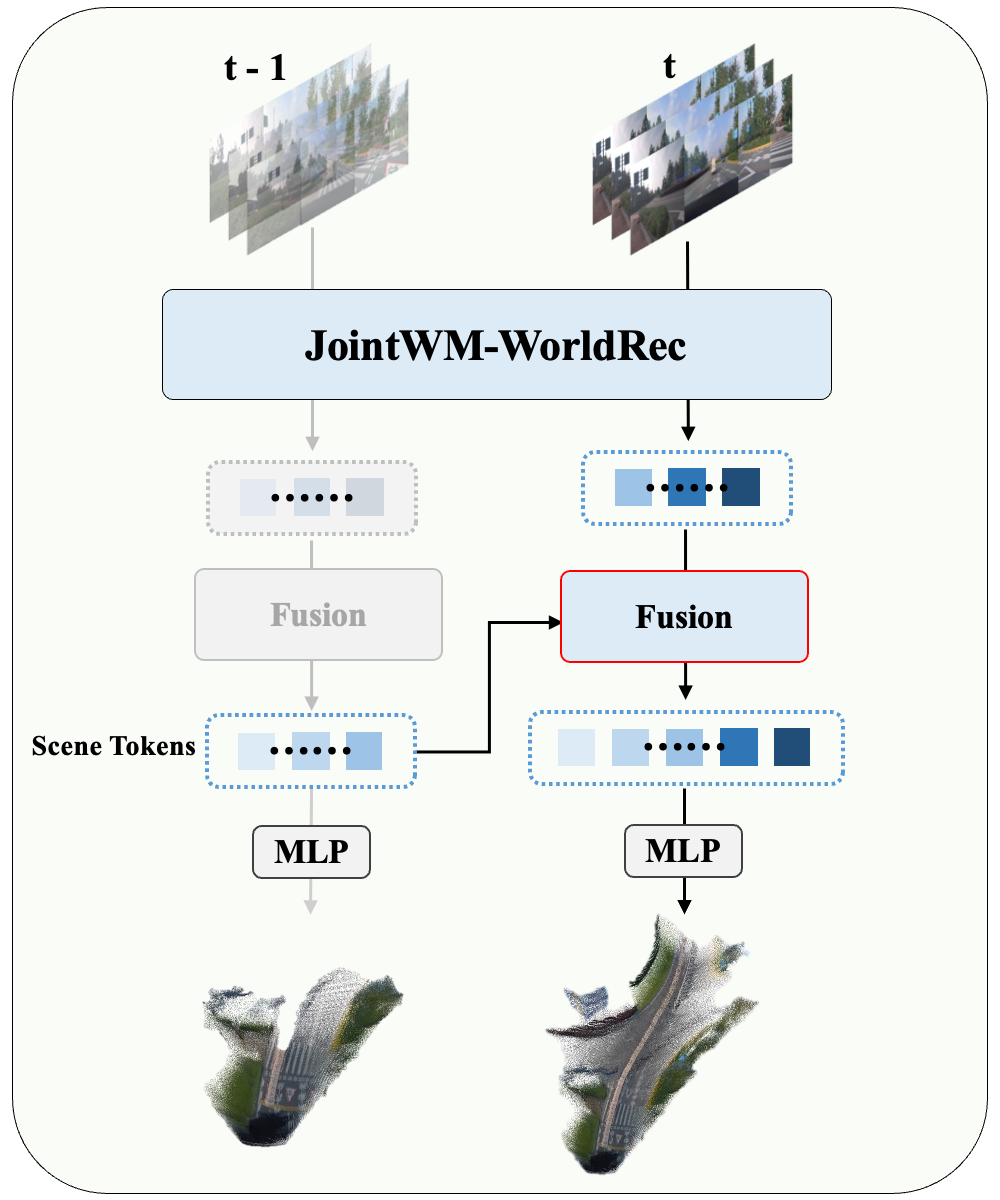
- High stability高稳定性: Deterministic geometric constraints from WorldRec suppress error accumulation and content drift during long-horizon autoregressive generation.:WorldRec 的确定性几何约束,有效抑制长时自回归中的误差累积与内容漂移。
- High consistency高一致性: The 4D scene representation acts as shared cross-frame memory, ensuring global consistency of object positions, lighting, and textures.:4D 场景表征作为跨帧共享记忆,确保不同时刻、不同视角下场景内容的全局一致性。
- High fidelity高真实性: Rich conditioning signals from WorldGen combined with reconstruction supervision bring synthesized content closer to real sensor observations.:WorldGen 丰富的条件信号结合重建模块的强监督,使合成内容更贴近真实传感器观测。
Results实验结果
3.1 WorldRec
Table 2 presents quantitative comparisons on Waymo and nuScenes. Our method achieves state-of-the-art performance across all settings. Reconstruction from a 10-second clip completes in ~10 seconds vs. ~4 hours for per-scene optimization.
表2展示了在 Waymo 和 nuScenes 上的定量对比,我们的方法在所有设置下均达到最优性能。10 秒片段重建约需 10 秒,而逐场景优化约需 4 小时。
Table 2: Quantitative results on Waymo and nuScenes (PSNR↑ / SSIM↑).
表2:Waymo 与 nuScenes 数据集定量结果(PSNR↑ / SSIM↑)。
| Method | Waymo | NuScenes Zero-Shot | NuScenes Fine-Tuning | |||
|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | |
| MVSSplat | 20.56 | 0.697 | 17.84 | 0.563 | — | — |
| NoPoSplat | 24.31 | 0.751 | 19.75 | 0.545 | — | — |
| DepthSplat | 23.26 | 0.696 | 19.52 | 0.601 | — | — |
| STORM | 26.38 | 0.794 | 17.77 | 0.669 | 24.54 | 0.784 |
| DGGT | 27.41 | 0.846 | 25.31 | 0.794 | 26.63 | 0.813 |
| Ours | 28.48 | 0.861 | 26.54 | 0.821 | 27.50 | 0.826 |
Driving-view reconstruction quality驾驶视角重建效果
Bird's-eye view reconstruction quality鸟瞰视角重建效果
3.2 WorldGen
Table 3 compares WorldGen against leading driving world models on nuScenes. As an autoregressive (AR) model, WorldGen achieves FID 7.04 and FVD 64.97, outperforming all listed models in FVD. It generates 81-frame sequences (far exceeding 8–16 frames of most baselines) at 0.19s/frame — 5.6× faster than the only other AR method (Epona at 1.06s/frame).
表3将 WorldGen 与主流驾驶世界模型在 nuScenes 上进行对比。作为自回归(AR)模型,WorldGen 实现 FID 7.04、FVD 64.97,在 FVD 上超越所有列出的模型。生成 81 帧序列(远超多数基线的 8-16 帧),推理速度 0.19 秒/帧,比唯一另一个 AR 方法 Epona(1.06 秒/帧)快 5.6 倍。
Table 3: Comparison of driving world models on nuScenes dataset.
表3:驾驶世界模型在 nuScenes 数据集上的对比。
| Model | Bi / AR双向 / 自回归 | Venue | FID↓ | FVD↓ | Frames | Infer. Time推理时间 |
|---|---|---|---|---|---|---|
| MagicDrive | Bi | ICLR'24 | 16.20 | — | 1 | — |
| MagicDrive-V2 | Bi | ICCV'25 | 20.91 | 94.84 | 16 | — |
| Vista | Bi | NeurIPS'24 | 6.9 | 89.4 | 16 | — |
| DiVE | Bi | arXiv'25 | 7.14 | 68.4 | 8 | — |
| Delphi | Bi | arXiv'24 | 15.08 | 113.5 | 8 | — |
| UniScene | Bi | CVPR'25 | 6.12 | 70.52 | 8 | — |
| Genesis | Bi | NeurIPS'25 | 6.45 | 67.87 | 16 | — |
| Epona | AR | ICCV'25 | 7.5 | 82.8 | 16 | 1.06s |
| WorldGen (Ours) | AR | — | 7.04 | 64.97 | 81 | 0.19s |
Long-tail animal scene generation长尾动物场景生成
Extreme weather scene generation极端天气场景生成
Controllable long-horizon video generation (10Hz/30Hz, up to 1 minute)可控长时序视频生成(10Hz/30Hz,时长可达 1 分钟)
3.3 Joint World Model联合世界模型
We evaluate the Joint World Model along three dimensions: long-horizon temporal consistency, multi-view spatial consistency, and multi-run stability. The geometric prior from WorldRec anchors the generative process, preventing drift and hallucination while maintaining globally coherent scene content.
我们从三个维度评估联合世界模型:长时序一致性、多视角空间一致性和多趟稳定性。WorldRec 的几何先验锚定生成过程,防止漂移和幻觉,保持全局一致的场景内容。
Long-horizon temporal consistency长时序一致性
Multi-view spatial consistency多视角空间一致性

Multi-run stability多趟稳定性
Conclusion总结
This report has systematically presented the technical designs and experimental results of WorldRec, WorldGen, and the Joint World Model.
WorldRec breaks through two long-standing bottlenecks — multi-hour per-scene optimization and Gaussian primitive explosion — by adopting a sparse-query-driven feed-forward paradigm, compressing reconstruction time from hours to seconds. WorldGen achieves high-quality long-horizon video generation with only 4 denoising steps through bidirectional pretraining followed by causal fine-tuning (Teacher Forcing → ODE distillation → DMD), while setting state-of-the-art FVD of 64.97 on nuScenes at 0.19s/frame inference speed. The Joint World Model organically integrates both: WorldRec's deterministic geometric constraints suppress generative drift, while WorldGen's rich imagination compensates for reconstruction limitations in unseen regions, achieving synergistic gains in stability, consistency, and fidelity.
The technical system presented in this report provides a complete solution for constructing high-quality autonomous driving world models suitable for closed-loop simulation, data synthesis, and end-to-end training.
本报告系统阐述了 WorldRec、WorldGen 及联合世界模型的技术方案与实验结果。
WorldRec 通过稀疏查询驱动的前馈重建范式,突破了逐场景优化耗时长、高斯基元数量爆炸的双重瓶颈,将重建时间从数小时压缩至秒级。WorldGen 通过"双向预训练 → 因果微调"的两阶段策略,仅用 4 步去噪实现高质量长时序视频生成,同时在 nuScenes 上以 0.19 秒/帧的推理速度达到 FVD 64.97 的最优性能。联合世界模型有机整合两者,在稳定性、一致性与保真度三个维度上实现协同增益。
本报告提出的技术体系为构建可用于闭环仿真、数据合成与端到端训练的高质量自动驾驶世界模型提供了完整解决方案。